NMF法による質量分析器を用いた近似臭作成方法-原理編
バーチャルリアリティー再現の一環として、香りを再生するシステムは、様々な分野で応用が期待されている。
当研究室では「匂いを自由に遠隔地で再現する装置・システム」を目指して研究を行ってきた。
匂いの情報を元に、その香りを要素臭とレシピを用いて調合する方法の開発を目指している。
香りは、異なる香りを混ぜて嗅ぐと異なるイメージの香りが作り出せることが知られている。
匂いの情報を元に、要素臭とそのレシピを用いて調合することが可能である。
このように、いくつもの現実の香りを再現するためには、香りの要素(要素臭)と現実の香りを再現するときの各係数を同時に考える方法を開発しなくてはならない。
香りの基本要素の探索が潜在的に求められているが、汎用的な要素臭はまだ明らかになっていない。
要素臭の探索においては官能検査に基づくのが最良であるが、膨大なデータを得るのは困難である。
以上を踏まえて当研究室では、質量分析器によるマススペクトルデータから汎用的な要素臭の探索を行い、
それらを用いたターゲット香気に対する近似臭の作成する研究について報告してきた。
質量分析器とは
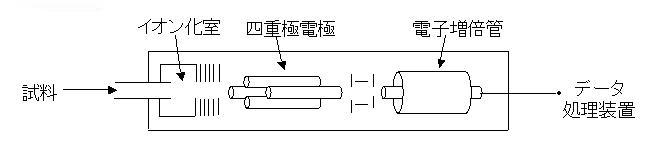
ここで、本研究で用いた質量分析器の原理(当研究室の質量分析器は、イオン化法はEI、分析部は四重極型である)について説明する。 図1に示すように、まず試料を導入しイオン化室で電子流を当てることによりイオン化する(EIイオン化法)。 次にここの四重極電極には交流電圧がかかっており、電圧の周波数を変化させることにより、検出器に到達できるイオンのm/z値が変化する。 四重極電極の交流を走査することにより、ある程度の時間分解能を持つ連続的なマススペクトルが得られる。
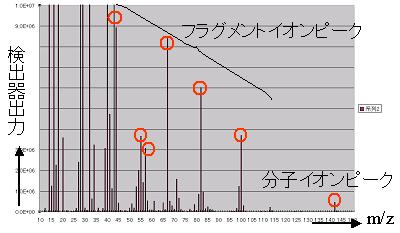
測定結果は図2のようになり横軸にはm/z、縦軸には検出信号強度を示している。 EIイオン化法は適用できる分子量範囲は1~1000程、試料の分子量を示す分子イオンピークの他に、 イオン化の際に起きる開裂によりフラグメントイオンが発生する。 この現象はフラグメンテーションと呼ばれ、マススペクトルは複雑になる。 各m/zのピークを1つのセンサ出力とみなしてマススペクトルをパターン認識することにより匂いの識別、濃度定量を行うことが出来る。
質量分析器による香り分析の特徴
匂いの記録・再生を実現するためには、対象臭のレシピを精度良く決定する必要がある。 水晶振動子センサでは、成分数が多い場合多重共線性の問題があり、質量分析器を用いて対象臭のレシピ測定に行う方法を採用した。 質量分析器は、複数成分のガスに対してすぐれた選択性および線形性が期待できるため、比較的容易にレシピ決定を行える可能性がある。 質量分析器での測定結果より得られるマススペクトルデータベースを用いて、匂い物質のレシピを探る。
NMF法を用いた要素臭の作成
様々な匂い物質を質量分析器で測定することで得られる大規模な香りデータベースから、
NMF法を用いて匂いの元となる要素臭データと係数を近似計算によって求める。
NMF(Non-Negative Matrix Factorization)法とは、元のデータの持つ情報量を可能な限り維持しつつ、データの次元を圧縮する方法である。
NMF法の具体的な計算内容を式(1)に示す。大規模なデータ(データ行列V)を少数のデータ(基底行列W)と係数行列(H)との積で近似的に表現することができる。
基底行列と係数行列に関する更新則を繰り返すことで近似の精度が向上する。
NMF法
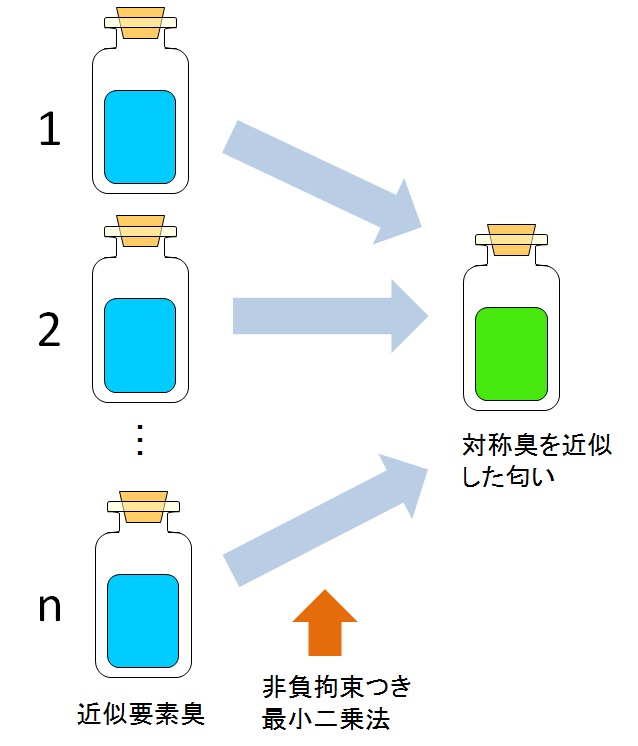
NMF法により得られた要素臭のマススペクトルを持つフレーバーを作成するために、 測定により得られた大規模な香りデータベースに 非負拘束つき最小二乗法を適用し、近似要素臭を作る。 マススペクトルデータベースから、近似要素臭を作成するための手順を図3に示す。
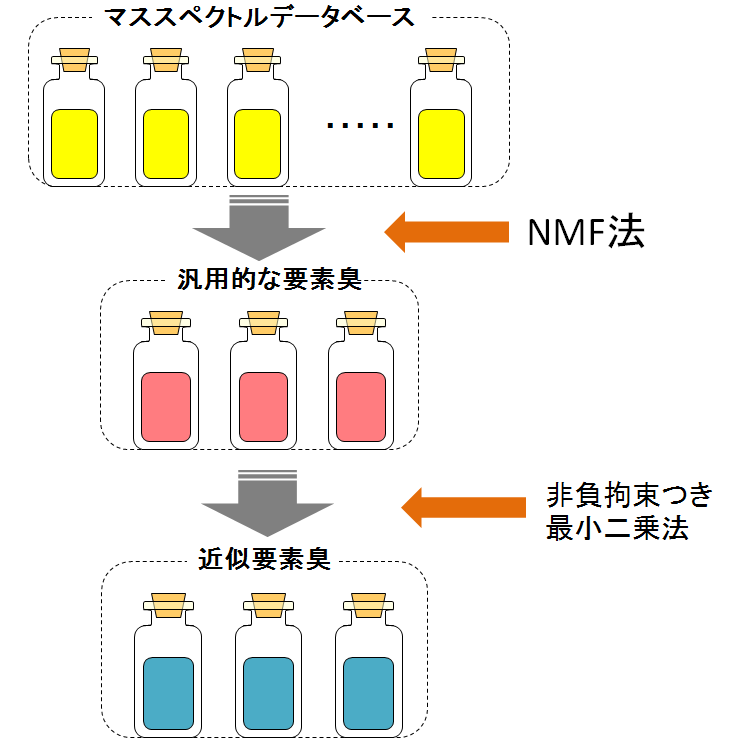
また、近似要素臭から対象の近似臭を作る流れを図4に示す。
NMF法による質量分析器を用いた近似臭作成方法-実験編
NMF法による質量分析器を用いた近似臭作成
香料は原料あるいは製法によって、まず天然香料と単体香料とに分けられ、さらに、天然香料は花や葉などからとる植物性香料と動物性香料とに分けられる。
調合は天然香料や合成香料をブレンドして、用途に合った一つのまとまった香りに仕上げることである。
香料は調合という観点からいくつかの香調に分類できる。
今回、一般的にその香りがよく知られているオリジナルの精油(オーガニックオレンジ、ペパーミント、ブラックペッパー)を対象臭として、
要素臭数が12と30の時の要素臭セットからそれぞれの近似臭を作成した。オーガニックオレンジ、ペパーミント、ブラックペッパーは、
一般的にその香りがよく知られているだけではなく、それぞれの精油が精油のカテゴリーの中でも異なるカテゴリーに属している。
調合実験結果
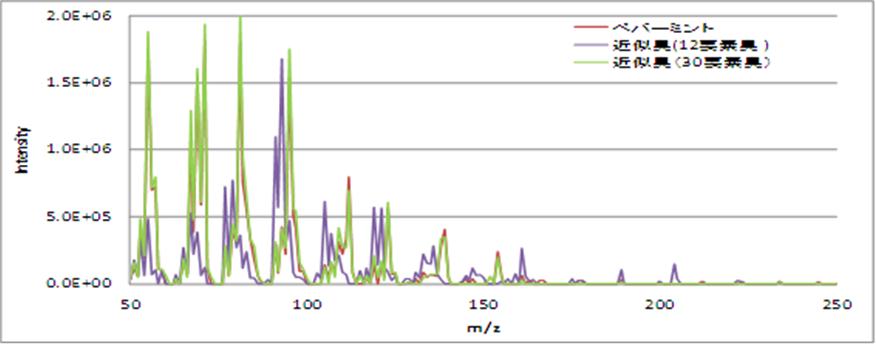
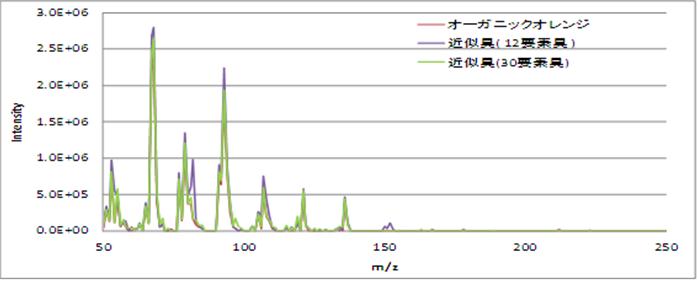
計算結果に従って近似臭を調合してみた結果、30要素臭の場合は対象臭と近似臭のマススペクトラムはほぼ一致した。
近似臭の精度とマススペクトル残差の関係
匂い物質のマススペクトルと、近似要素臭から作成した近似臭のマススペクトルとの間の残差が、小さければ小さいほど、
対象となる匂い物質を再現できていると考えられる。官能検査を行い、近似要素臭の精度と残差の関係を調べた。
図7に、研究室のメンバーを対象にして、三点識別法により行われた官能検査の結果を示す。
この方法は、対象となる匂い物質を2つと、それの 近似臭を1つ用意して、3つの匂い物質から近似臭を嗅ぎ分けてもらうという方法である。
つまり、近似臭の再現性が良ければ、識別率は33%に近づくと考えられる。
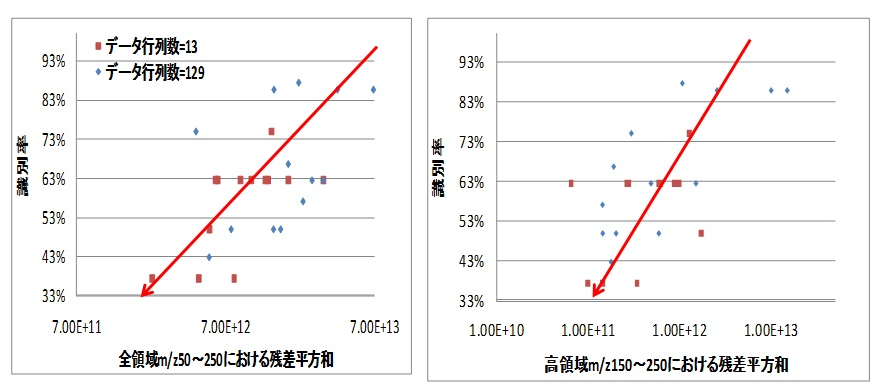
残差と近似臭の精度の程度にはある程度相関がある事が分かる。また右の図より、m/zが高領域の方が識別率が残差に大きく影響されていると考えられる。
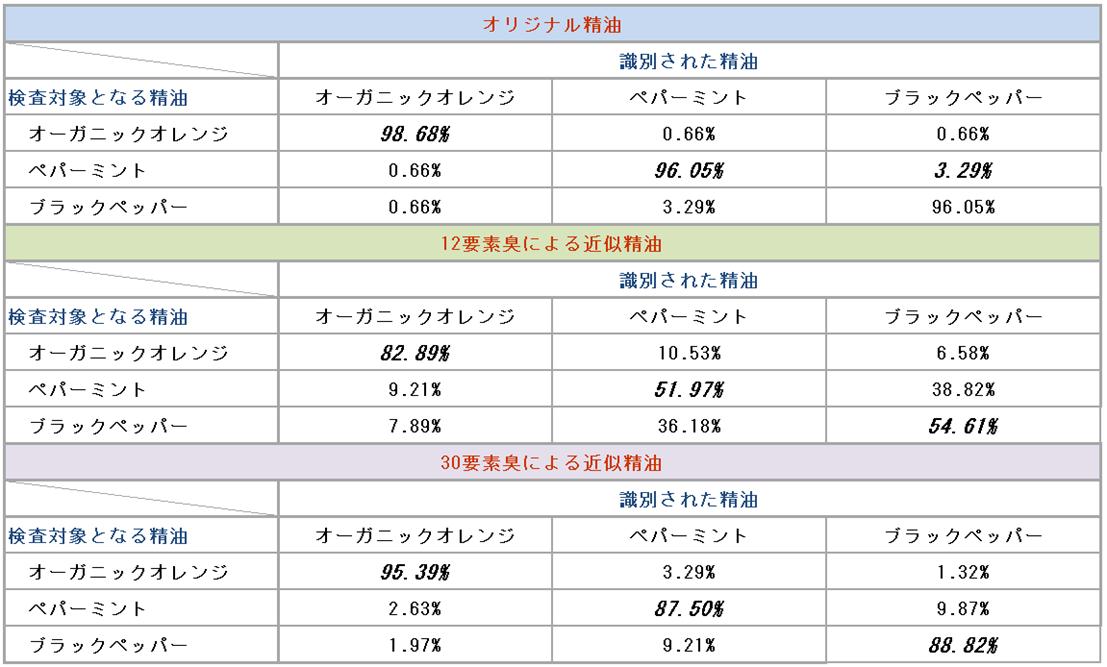
官能評価( 2010年工大祭にて 一般の方172人に対して実施した結果)
要素臭が12及び30の場合のオリジナル精油と近似精油の識別率(精油:オーガニックオレンジ、 ペパーミント、ブラックペッパー) 12要素臭の場合は識別率が不十分だが、30要素臭では十分な識別率が得られた。 また、対象臭としてオーガニックオレンジ、ペパーミント、ブラックペッパー精油を使用して、 12種類の要素臭から作成した近似臭と30種類の要素臭から作成した近似臭の近似精度の差が人間の嗅覚に対して与える影響を官能検査により調査した。 結果を表2に示す。なお、この実験の被験者は工大祭に来て頂いた172人の男女である。 30種類の要素臭から作成した近似臭は被験者がそれぞれの近似臭を高い精度で嗅ぎ分けることが可能であることを示した。